
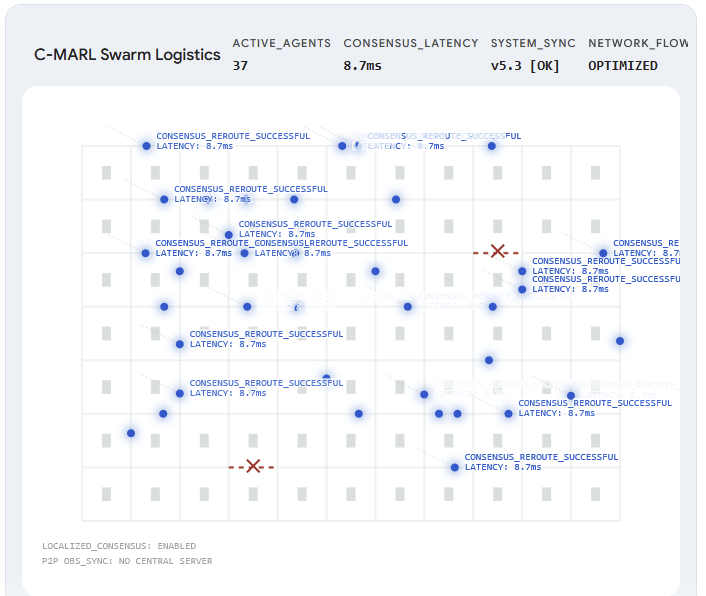
Coordination décentralisée via C-MARL
RideFair utilise l'apprentissage parrenforcement multi-agents coopératif (C-MARL). Au lieu qu'un serveur centraliséprenne toutes les décisions de routage, les véhicules individuels (agents)partagent des signaux locaux et négocient des flux optimaux. Lorsqu'un goulotd'étranglement survient, l'intelligence en essaim le détecte et reroutage letrafic instantanément via un consensus local, avec des boucles de décisioninférieures à 10 ms.
Principes fondamentaux
➤
Simulation en premier: Tous les modèles sont rigoureusement testés dans des environnements synthétiques avant d'être appliqués au monde réel.
➤
Validation par les données: Les modes de relecture permettent aux opérateurs d'évaluer les performances théoriques par rapport aux données de référence historiques.
➤
Confidentialité dès la conception: Le traitement décentralisé réduit au minimum le besoin de centralisation des données.
Ce que nous construisons actuellement
➤
Avril–Juin 2026: Démonstration de 12 semaines axée sur la simulation pour établir des métriques avant/après.
➤
Juillet–Août 2026: Développement du pipeline de partenaires et cadrage des pilotes terrain.
➤
Septembre–Décembre 2026: Intégration en mode fantôme et déploiement MVP avec des partenaires locaux.